

Choosing the Right LLM for Your Use Case! 🚀

Do you rely on the same LLM for every use case? 🤔
If YES, it’s time to rethink your approach!
✅ LLM Benchmarks help you find the best models for specific tasks.
💯 This guide will help you make smarter choices!

HOW LLMs ARE EVALUATED
📌 LLMs are rigorously tested across multiple domains to assess their problem-solving capabilities, accuracy, and overall effectiveness. These evaluations ensure that the chosen model aligns with specific use cases and delivers reliable results.
Key Evaluation Areas:
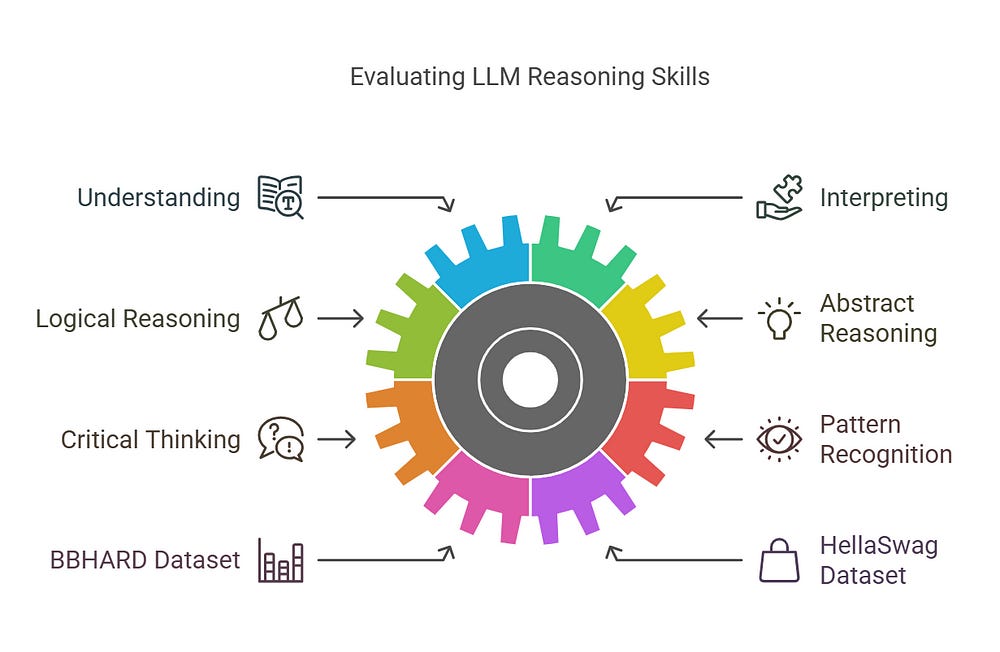
✅ REASONING (Common Sense & Logical Thinking) 🧠
Measures an LLM’s ability to understand, interpret, and reason logically based on context.
Includes abstract reasoning, critical thinking, and pattern recognition.
Benchmarked using datasets like BBHARD and HellaSwag.
🔹 Example: Can the LLM deduce that “if A is bigger than B, and B is bigger than C, then A is bigger than C”?
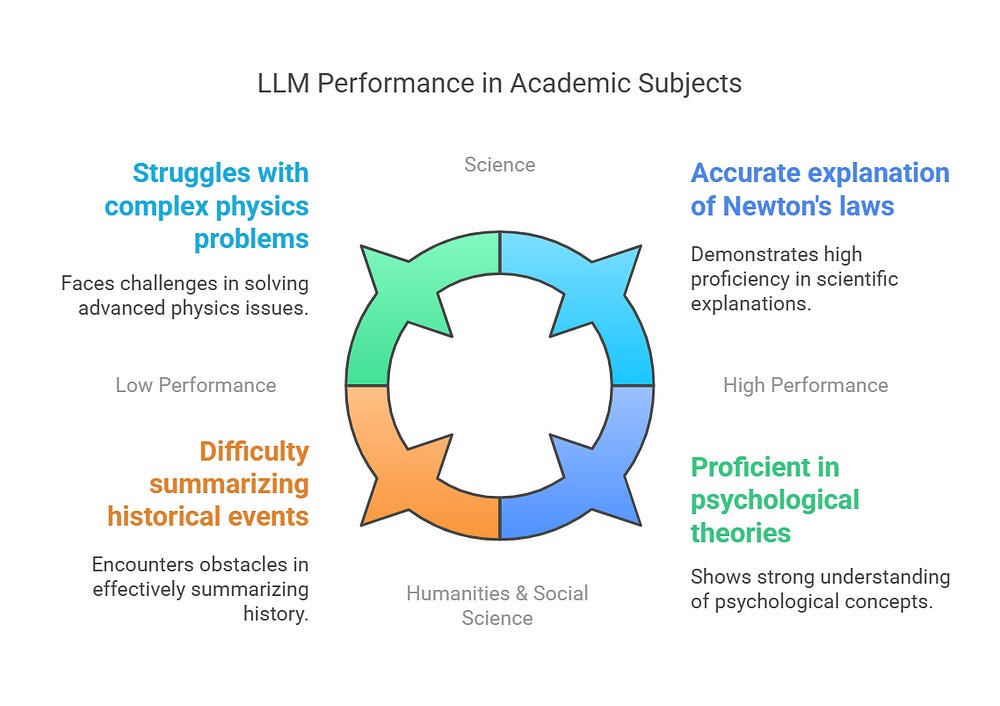
✅ STEM & SOCIAL SCIENCES (Science, Math, Humanities) 📚
Tests LLM performance across structured academic subjects, including:
📐 Mathematics (Algebra, Calculus, Probability)
🧪 Science (Physics, Chemistry, Biology)
📖 Humanities & Social Science (History, Literature, Psychology)
Benchmarked using the MMLU (Massive Multitask Language Understanding) dataset.
🔹 Example: Can the LLM accurately explain Newton’s laws or summarize historical events?
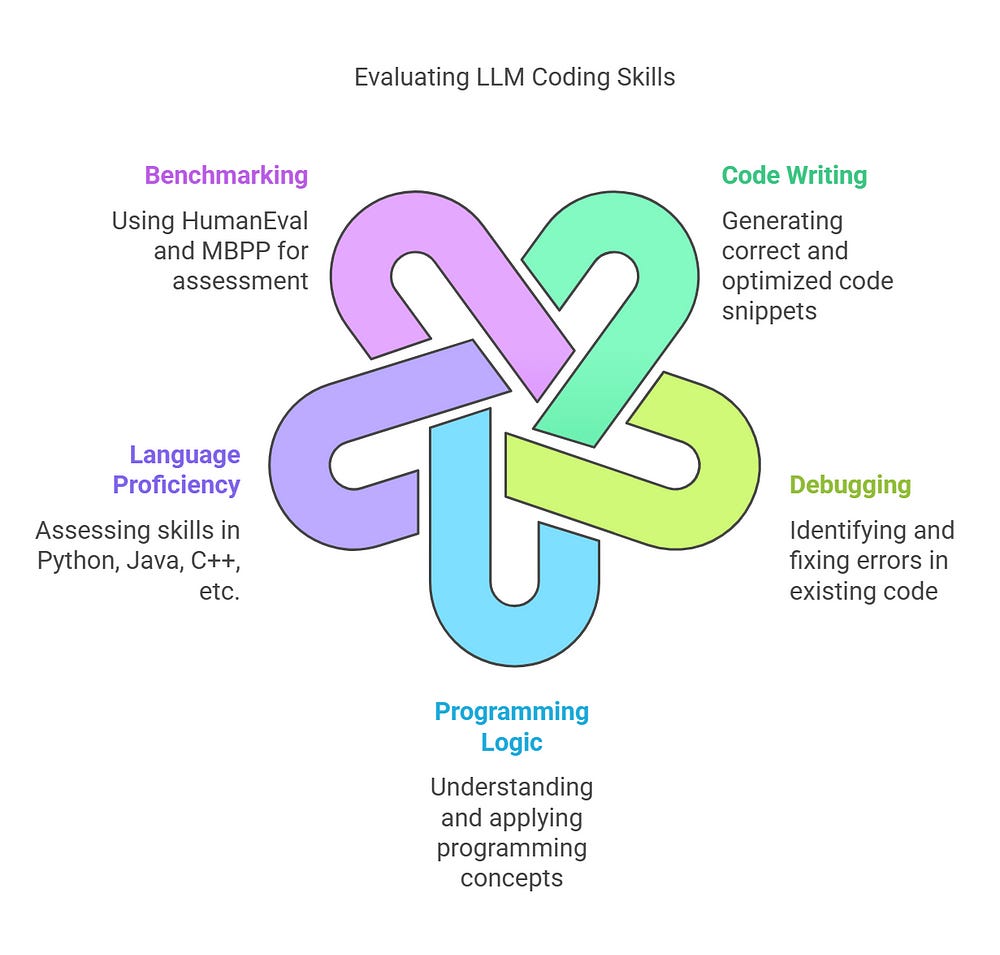
✅ PROGRAMMING (Code Generation & Problem-Solving) 💻
Evaluates an LLM’s ability to write, debug, and optimize code across different programming languages.
Assesses proficiency in Python, Java, C++, and other languages for tasks like:
✅ Generating correct & optimized code snippets
✅ Debugging existing code
✅ Understanding programming logic
Benchmarked using HumanEval and MBPP (Multi-Turn Benchmark for Programming Proficiency).
🔹 Example: Can the LLM write a function to reverse a linked list in Python?
✅ APPLICATIONS (Real-World Scenarios & Task-Specific Performance) 🌍
Measures an LLM’s ability to apply knowledge to real-world situations, including:
🔍 Document summarization
🤖 Chatbot interactions & Customer Support
🌍 Multilingual Translation & Cross-Cultural Understanding
🏥 Healthcare and Legal AI Applications
Benchmarked using various domain-specific datasets tailored for practical implementation.
🔹 Example: Can the LLM summarize a legal contract accurately while retaining critical clauses?
🚀 WHY THIS MATTERS?
Choosing an LLM that excels in your target domain ensures:
✅ Higher accuracy & relevance in responses
✅ Faster and more efficient task execution
✅ Reduced errors and improved decision-making
Selecting the right LLM is crucial for optimizing AI-driven solutions! 💡
TOP LLM BENCHMARKS & LEADERS
📊 KEY BENCHMARKS & BEST-PERFORMING MODELS:
🔹 MMLU (STEM, Humanities, etc.)
📌 Top Models: Gemini Ultra, GPT-4o, Claude 3 Opus
🔹 HellaSwag (Common Sense Reasoning)
📌 Top Models: CompassMTL, GPT-4, Llama 3
🔹 HumanEval (Programming & Coding)
📌 Top Models: LDB, AgentCoder, Claude Sonnet 3.5
🔹 BBHARD (Logical Reasoning & Common Sense)
📌 Top Models: Claude Sonnet 3.5
🔹 GSM-8K (Mathematics Problem-Solving)
📌 Top Models: GPT-4, Mistral 7B, Damomath
📌 Both Closed & Open-Source Models Included!
WHY THIS MATTERS?
🔥 CHOOSING THE RIGHT LLM = BETTER RESULTS!
✅ Optimize Performance for Your Specific Use Case
✅ Pick the Right Model — Open-Source or Closed?
✅ Enhance Accuracy, Efficiency & Output Quality
✅ Stay Ahead in AI Innovation! 🚀
👉 Looking to Upskill in Generative AI?
Check out the learning resources at HiDevs.xyz🔗 Join the HiDevs Community:
LinkedIn Community: HiDevs LinkedIn
WhatsApp Group: Join HiDevs on WhatsApp
YouTube: Do subscibe
Instagram: Do Follow
DON’T RELY ON ONE-SIZE-FITS-ALL!
🔍 Use Benchmarks to Choose the BEST LLM for Your Needs
🚀 Stay Updated on the Latest in Gen AI